Lab 4a: Mapping Open Data
CRD 230 - Spatial Methods in Community Research
Professor Noli Brazil
January 30, 2023
In Lab 3, you learned how to process spatial data in R, focusing primarily on reading in, wrangling and mapping areal or polygon data. In this lab, we will cover point data in R. More broadly, we will cover how to access and clean data from Open Data portals and OpenStreetMap. In Lab 4b, we will learn how to process Big Data using Twitter Tweets as a case example. The objectives of this guide are
- Learn how to read in point data
- Understand Coordinate Reference Systems
- Learn how to reproject spatial data
- Learn how to bring in data from OpenStreetMap
- Learn how to map point data
To achieve these objectives, we will first examine the spatial distribution of homeless encampments in the City of Los Angeles using 311 data downloaded from the city’s open data portal. This lab guide follows closely and supplements the material presented in Chapters 2.4, 4.2, 7 and 8 in the textbook Geocomputation with R (GWR) and class Handout 3.
Installing and loading packages
You’ll need to install the following packages in R. You only need to
do this once, so if you’ve already installed these packages, skip the
code. Also, don’t put these install.packages() in your R
Markdown document. Copy and paste the code in the R Console.
install.packages(c("tidygeocoder",
"osmdata"))You’ll need to load the following packages. Unlike installing, you
will always need to load packages whenever you start a new R
session. You’ll also always need to use library() in your R
Markdown file.
library(sf)
library(tidyverse)
library(units)
library(tmap)
library(tidycensus)
library(tigris)
library(rmapshaper)
library(leaflet)
library(tidygeocoder)
library(osmdata)Read in census tract data
We will need to bring in census tract polygon features and racial
composition data from the 2015-2019 American Community Survey using the
Census API and keep tracts within Los Angeles city boundaries using a
clip. The code for accomplishing these tasks is below. We won’t go
through each line of code in detail because we’ve covered all of these
operations and functions in prior labs. I’ve embedded comments within
the code that briefly explain what each chunk is doing, but go back to
prior guides (or RDS/GWR) if you need further help. The only new code I
use is rename_with(~ sub("E$", "", .x), everything()) to
eliminate the E at the end of the variable names for the
estimates.
# Bring in census tract data.
ca.tracts <- get_acs(geography = "tract",
year = 2019,
variables = c(tpop = "B01003_001", tpopr = "B03002_001",
nhwhite = "B03002_003", nhblk = "B03002_004",
nhasn = "B03002_006", hisp = "B03002_012"),
state = "CA",
survey = "acs5",
output = "wide",
geometry = TRUE)
# Make the data tidy, calculate percent race/ethnicity, and keep essential vars.
ca.tracts <- ca.tracts %>%
rename_with(~ sub("E$", "", .x), everything()) %>%
mutate(pnhwhite = nhwhite/tpopr, pnhasn = nhasn/tpopr,
pnhblk = nhblk/tpopr, phisp = hisp/tpopr) %>%
dplyr::select(c(GEOID,tpop, pnhwhite, pnhasn, pnhblk, phisp))
# Bring in city boundary data
pl <- places(state = "CA", year = 2019, cb = TRUE)
# Keep LA city
la.city <- filter(pl, NAME == "Los Angeles")
#Clip tracts using LA boundary
la.city.tracts <- ms_clip(target = ca.tracts, clip = la.city, remove_slivers = TRUE)Read in point data
Point data are the building blocks of object or vector data. They give us the locations of objects or events within an area. Events can be things like crimes and car accidents. Objects can be things like trees, houses, jump bikes or even people, such as the locations of where people were standing during a protest.
Often you will receive point data in tabular (non-spatial) form. These data can be in one of two formats
- Point longitudes and latitudes (or X and Y coordinates)
- Street addresses
If you have longitudes and latitudes, you have all the information you need to make the data spatial. This process involves using geographic coordinates (longitude and latitude) to place points on a map. In some cases, you won’t have coordinates but street addresses. Here, you’ll need to geocode your data, which involves converting street addresses to geographic coordinates. These tasks are intimately related to the concept of projection and reprojection, and underlying all of these concepts is the Coordinate Reference System.
Longitude/Latitude
Best case scenario is that you have a point data set with geographic coordinates. Geographic coordinates are in the form of a longitude and latitude, where longitude is your X coordinate and spans East/West and latitude is your Y coordinate and spans North/South.
Let’s bring in a csv data set of homeless encampments in Los Angeles
City, which was downloaded from the Los
Angeles City Open Data portal. I uploaded the data set on GitHub so
you can directly read it in using read_csv(). If you’re
having trouble bringing this data in, I uploaded the file onto Canvas in
the Week 4 - Lab folder.
homeless.df <- read_csv("https://raw.githubusercontent.com/crd230/data/master/homeless311_la_2019.csv")
#take a look at the data
glimpse(homeless.df)## Rows: 55,536
## Columns: 34
## $ SRNumber <chr> "1-1523590871", "1-1523576655", "1-152357498…
## $ CreatedDate <chr> "12/31/2019 11:26:00 PM", "12/31/2019 09:27:…
## $ UpdatedDate <chr> "01/14/2020 07:52:00 AM", "01/08/2020 01:42:…
## $ ActionTaken <chr> "SR Created", "SR Created", "SR Created", "S…
## $ Owner <chr> "BOS", "BOS", "BOS", "BOS", "BOS", "LASAN", …
## $ RequestType <chr> "Homeless Encampment", "Homeless Encampment"…
## $ Status <chr> "Closed", "Closed", "Closed", "Closed", "Clo…
## $ RequestSource <chr> "Mobile App", "Mobile App", "Mobile App", "M…
## $ CreatedByUserOrganization <chr> "Self Service", "Self Service", "Self Servic…
## $ MobileOS <chr> "iOS", "Android", "iOS", "iOS", "iOS", NA, "…
## $ Anonymous <chr> "N", "Y", "Y", "Y", "Y", "N", "N", "N", "N",…
## $ AssignTo <chr> "WV", "WV", "WV", "WV", "WV", "NC", "WV", "W…
## $ ServiceDate <chr> "01/14/2020 12:00:00 AM", "01/10/2020 12:00:…
## $ ClosedDate <chr> "01/14/2020 07:51:00 AM", "01/08/2020 01:42:…
## $ AddressVerified <chr> "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y",…
## $ ApproximateAddress <chr> NA, NA, NA, NA, NA, "N", NA, NA, NA, NA, "N"…
## $ Address <chr> "CANOGA AVE AT VANOWEN ST, 91303", "23001 W …
## $ HouseNumber <dbl> NA, 23001, NA, 5550, 5550, NA, 5200, 5500, 2…
## $ Direction <chr> NA, "W", NA, "N", "N", NA, "N", "N", "S", "W…
## $ StreetName <chr> NA, "VANOWEN", NA, "WINNETKA", "WINNETKA", N…
## $ Suffix <chr> NA, "ST", NA, "AVE", "AVE", NA, "AVE", "AVE"…
## $ ZipCode <dbl> 91303, 91307, 91367, 91364, 91364, 90004, 91…
## $ Latitude <dbl> 34.19375, 34.19388, 34.17220, 34.17143, 34.1…
## $ Longitude <dbl> -118.5975, -118.6281, -118.5710, -118.5707, …
## $ Location <chr> "(34.1937512753, -118.597510305)", "(34.1938…
## $ TBMPage <dbl> 530, 529, 560, 560, 560, 594, 559, 559, 634,…
## $ TBMColumn <chr> "B", "G", "E", "E", "E", "A", "H", "J", "B",…
## $ TBMRow <dbl> 6, 6, 2, 2, 2, 7, 3, 2, 6, 3, 3, 2, 7, 3, 2,…
## $ APC <chr> "South Valley APC", "South Valley APC", "Sou…
## $ CD <dbl> 3, 12, 3, 3, 3, 13, 3, 3, 1, 3, 7, 3, 3, 4, …
## $ CDMember <chr> "Bob Blumenfield", "John Lee", "Bob Blumenfi…
## $ NC <dbl> 13, 11, 16, 16, 16, 55, 16, 16, 76, 16, 101,…
## $ NCName <chr> "CANOGA PARK NC", "WEST HILLS NC", "WOODLAND…
## $ PolicePrecinct <chr> "TOPANGA", "TOPANGA", "TOPANGA", "TOPANGA", …The data represent homeless encampment locations in 2019 as reported through the City’s 311 system. 311 is a centralized call center that residents, businesses and visitors can use to request service, report problems or get information from local government. To download the data from LA’s open data portal linked above, I did the following
- Navigate to the the following website. Click on View Data. This will bring up the data in an excel style worksheet.
- You’ll find that there are over one million 311 requests in 2019. Rather than bringing all of these requests into R, let’s just filter for homeless encampments. To do this, on the right hand side of your screen, click on Filter, Add a New Filter Condition, select Request Type from the first pull down menu, then type in Homeless Encampment in the first text box.
- Click on Export and select CSV. Download the file into an appropriate folder on your hard drive.
Viewing the file and checking its class you’ll find that homeless.df is a regular tibble (no geometry column), not a spatial sf points object.
We will use the function st_as_sf() to create a point
sf object of homeless.df. The function
requires you to specify the longitude and latitude of each point using
the coords = argument, which are conveniently stored in the
variables Longitude and Latitude.
homeless.sf <- homeless.df %>%
st_as_sf(coords = c("Longitude", "Latitude"))Street Addresses
Often you will get point data that won’t have longitude/X and latitude/Y coordinates but instead have street addresses. The process of going from address to X/Y coordinates is known as geocoding.
To demonstrate geocoding, type in your home street address, city and state inside the quotes below.
myaddress.df <- tibble(street = "", city = "", state = "")This creates a tibble with your street, city and state saved in three
variables. To geocode addresses to longitude and latitude, use the
function geocode() which is a part of the
tidygeocoder package. Use geocode() as
follows
myaddress.df <- myaddress.df %>%
geocode(street = street, city = city, state = state, method = "census")Here, we specify street, city and state variables. The argument
method = 'census' specifies the geocoder used to map
addresses to longitude/latitude locations. In the above case
'census' uses the geocoder provided by the U.S. Census to
find the address. Think of a geocoder as R going to the Census geocoder
website, searching for
each address, plucking the latitude and longitude of the address, and
saving it into a tibble named myaddress.df. Other geocoders
include Google Maps (requires an API key) and OpenStreetMap.
If you view this object, you’ll find the latitude lat and
longitude long attached as columns. Convert this point to an
sf object using the function
st_as_sf().
myaddress.sf <- myaddress.df %>%
st_as_sf(coords = c("long", "lat"))Type in tmap_mode("view") and then map
myaddress.sf. Zoom into the point. Did it get your home address
correct?
Let’s bring in a csv file containing the street addresses of homeless shelters and services in Los Angeles County , which I also downloaded from Los Angeles’ open data portal. This file is also on Canvas.
shelters.df <- read_csv("https://raw.githubusercontent.com/crd230/data/master/Homeless_Shelters_and_Services.csv")
#take a look at the data
glimpse(shelters.df)## Rows: 182
## Columns: 23
## $ source <chr> "211", "211", "211", "211", "211", "211", "211", "211", "…
## $ ext_id <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ cat1 <chr> "Social Services", "Social Services", "Social Services", …
## $ cat2 <chr> "Homeless Shelters and Services", "Homeless Shelters and …
## $ cat3 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ org_name <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, "www.catalystfdn.org"…
## $ Name <chr> "Special Service For Groups - Project 180", "1736 Family…
## $ addrln1 <chr> "420 S. San Pedro", "2116 Arlington Ave", "1736 Monterey …
## $ addrln2 <chr> NA, "Suite 200", NA, NA, NA, NA, "4th Fl.", NA, NA, NA, N…
## $ city <chr> "Los Angeles", "Los Angeles", "Hermosa Beach", "Monrovia"…
## $ state <chr> "CA", "CA", "CA", "CA", "CA", "CA", "CA", "CA", "CA", "CA…
## $ hours <chr> "SITE HOURS: Monday through Friday, 8:30am to 4:30pm.", …
## $ email <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ url <chr> "ssgmain.org/", "www.1736fcc.org", "www.1736fcc.org", "ww…
## $ info1 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ info2 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ post_id <dbl> 772, 786, 788, 794, 795, 946, 947, 1073, 1133, 1283, 1353…
## $ description <chr> "The agency provides advocacy, child care, HIV/AIDS servi…
## $ zip <dbl> 90013, 90018, 90254, 91016, 91776, 90028, 90027, 90019, 9…
## $ link <chr> "http://egis3.lacounty.gov/lms/?p=772", "http://egis3.lac…
## $ use_type <chr> "publish", "publish", "publish", "publish", "publish", "p…
## $ date_updated <chr> "2017/10/30 14:43:13+00", "2017/10/06 16:28:29+00", "2017…
## $ dis_status <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…The file contains no latitude and longitude data, so we need to
convert the street addresses contained in the variables
addrln1, city and state. Use the function
geocode(). The process may take a few minutes so be patient.
shelters.geo <- shelters.df %>%
geocode(street = addrln1, city = city, state = state, method = 'census')Look at the column names.
names(shelters.geo)## [1] "source" "ext_id" "cat1" "cat2" "cat3"
## [6] "org_name" "Name" "addrln1" "addrln2" "city"
## [11] "state" "hours" "email" "url" "info1"
## [16] "info2" "post_id" "description" "zip" "link"
## [21] "use_type" "date_updated" "dis_status" "lat" "long"We see the latitudes and longitudes are attached to the variables lat and long, respectively. Notice that not all the addresses were successfully geocoded.
summary(shelters.geo$lat)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 33.74 33.99 34.05 34.07 34.10 34.70 16Several shelters received an NA. This is likely because
the addresses are not correct, has errors, or are not fully specified.
You’ll have to manually fix these issues, which becomes time consuming
if you have a really large data set. You can also try another geocoder.
For the purposes of this lab, let’s just discard these, but in practice,
make sure to double check your address data (See the document
Geocoding_Best_Practices.pdf in the Other Resources folder on Canvas for
best practices for cleaning address data).
shelters.geo <- shelters.geo %>%
filter(is.na(lat) == FALSE & is.na(long) == FALSE)Convert latitude and longitude data into spatial points using the
function st_as_sf().
shelters.sf <- shelters.geo %>%
st_as_sf(coords = c("long", "lat"))In this section, you learned about geocoding using tidygeocoder. Here’s a badge for your R lapel!

Coordinate Reference System
Plot homeless encampments and shelters using functions from the tmap package, which we learned about in Lab 3. This is an example of a basic pin or dot map.
#turn mapping back to plot view
tmap_mode("plot")
#dot map
tm_shape(homeless.sf) +
tm_dots(col="red") +
tm_shape(shelters.sf) +
tm_dots(col="blue")## Warning: Currect projection of shape homeless.sf unknown. Long-lat (WGS84) is
## assumed.## Warning: Currect projection of shape shelters.sf unknown. Long-lat (WGS84) is
## assumed.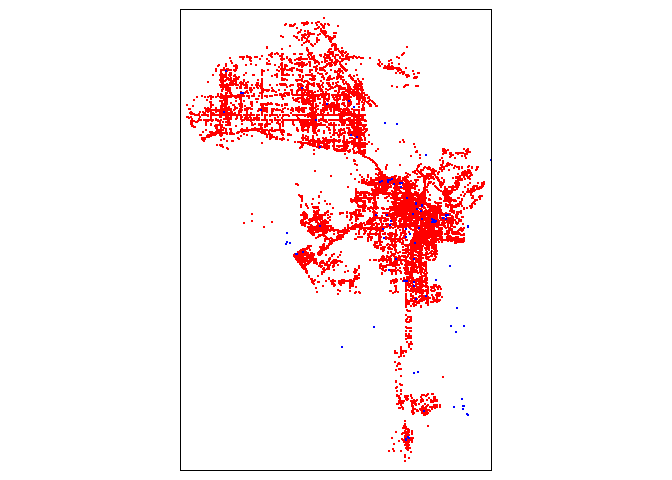
We get a map that looks correct. But, we did get two warnings. These warnings are not something to sneeze at - they tell us that we haven’t set a projection, which is no problem if we’re just mapping, but is no good if we want to do some spatial analyses on the point locations.
What we need to do is set the Coordinate Reference System (CRS). The CRS is an important concept to understand when dealing with spatial data. We won’t go through the real nuts and bolts of CRS, which you can read in GWR Chapters 2.4 and 7, but we’ll go through enough of it so that you can get through most of the CRS related spatial data wrangling tasks in this class. In addition to GWR, Esri also has a nice explanation here. This site also does a thorough job of explaining how to work with CRS in R. You can also read the document Coordinate_Reference_Systems.pdf on Canvas in the Other Resources folder.
The CRS contains two major components: the Geographic Coordinate System (GCS) and the Projected Coordinate System (PCS). A GCS uses a three-dimensional spherical surface to define locations on the earth. The GCS is composed of two parts: the ellipse and the datum. The ellipse is a model of the Earth’s shape - how the earth’s roundness is calculated. The datum defines the coordinate system of this model - the origin point and the axes. You need these two basic components to place points on Earth’s three-dimensional surface. Think of it as trying to create a globe (ellipse) and figuring out where to place points on that globe (datum).
The PCS then translates these points from a globe onto a two-dimensional space. We need to do this because were creating flat-paper or on-the-screen maps, not globes (it’s kind of hard carrying a globe around when you’re finding your way around a city).
You can find out the CRS of a spatial data set using the function
st_crs().
st_crs(homeless.sf)## Coordinate Reference System: NA
When we used st_as_sf() above to create
homeless.df, we did not specify a CRS. We should have. Working
with spatial data requires both a Geographic Coordinate System (so you
know where your points are on Earth) and a Projection (a way of putting
points in 2 dimensions). Both. Always. Like Peanut Butter and Jelly.
Like Sonny and Cher.
There are two common ways of specifying a coordinate system in R: via
the EPSG numeric code or via the PROJ4 formatted string. The
PROJ4 syntax consists of a list of parameters, each separated by a space
and prefixed with the + character. To specify the PCS, you
use the argument +proj=. To specify the GCS, you use the
arguments +ellps= to establish the ellipse and
+datum= to specify the datum.
How do we know which CRS to use? The most common datums in North
America are NAD27, NAD83 and WGS84, which has the ellipsoids clrk66,
GRS80, and WGS84, respectively. The datum always specifies the ellipsoid
that is used, but the ellipsoid does not specify the datum. This means
you can specify +datum= and not specify
+ellps= and R will know what to do, but not always the
other way around. For example, the ellipsoid GRS80 is also associated
with the datum GRS87, so if you specify ellps=GRS80 without
the datum, R won’t spit out an error, but will give you an unknown CRS.
The most common datum and ellipsoid combinations are listed in Figure 1
in the Coordinate_Reference_Systems.pdf document on Canvas.
When you are bringing in point data with latitude and longitude, the
projected coordinate system is already set for you. Latitudes and
longitudes are X-Y coordinates, which is essentially a Plate
Carree projection. You specify a PCS using the argument (in quotes)
+proj=longlat. Let’s use st_as_sf() again on
homeless.df, but this time specify the CRS using the argument
crs.
homeless.sf <- homeless.df %>%
st_as_sf(coords = c("Longitude", "Latitude"),
crs = "+proj=longlat +datum=WGS84 +ellps=WGS84")The CRS should have spaces only in between
+proj=longlat, +datum=WGS84 and
+ellps=WGS84, and no other place. Remember, you could have
just specified +datum=WGS84 and R would have known what to
do with the ellipsoid. What is the CRS now?
st_crs(homeless.sf)We can see the PROJ4 string using
st_crs(homeless.sf)$proj4string## [1] "+proj=longlat +datum=WGS84 +no_defs"Instead of a PROJ4, we can specify the CRS using the EPSG associated
with a GCS and PCS combination. A EPSG is a four-five digit unique
number representing a particular CRS definition. The EPSG for the
particular GCS and PCS combination used to create homeless.sf
is 4326. Had we looked this up here (another
useful site here), we could have used
crs = 4326 instead of
"+proj=longlat +datum=WGS84" in st_as_sf() as
we do below.
homeless.sf2 <- homeless.df %>%
st_as_sf(coords = c("Longitude", "Latitude"), crs = 4326)we verify that the CRS are the same
st_crs(homeless.sf) == st_crs(homeless.sf2)## [1] TRUELet’s set the CRS for the homeless shelter and services points.
shelters.sf <- shelters.geo %>%
st_as_sf(coords = c("long", "lat"), crs = 4326)Another important problem that you may encounter is that a shapefile
or any spatial data set you downloaded from a source contains no CRS
(unprojected or unknown). In this case, use the function
st_set_crs() to set the CRS. See GWR 7.3 for more
details.
Reprojection
The above section deals with a situation where you are establishing the CRS for the first time. However, you may want to change an already defined CRS. This task is known as reprojection. Why would you want to do this? There are three main reasons:
- Two spatial objects that are compared or combined have a different CRS.
- Many geometric functions require a certain CRS.
- Aesthetic purposes and/or to correct distortions.
Reason 1: All spatial data in your current R session should have the same CRS if you want to overlay the objects on a map or conduct any of the multiple layer spatial operations we went through in Lab 3.
Let’s check to see if homeless.sf and shelters.sf have the same CRS
st_crs(homeless.sf) == st_crs(shelters.sf)## [1] TRUEGreat. Do they match with la.city.tracts
st_crs(homeless.sf) == st_crs(la.city.tracts)## [1] FALSEOh no! If you map homeless.sf and la.city.tracts, you’ll find that they may align. R is smart enough to reproject on the fly to get them on the same map. However, this does not always happen. Furthermore, R doesn’t actually change the CRS. This leads to the next reason why we may need to reproject.
Many of R’s geometric functions that require calculating distances
(e.g. distance from one point to another) or areas require a standard
measure of distance/area. The spatial point data of homeless encampments
are in longitude/latitude coordinates. Distance in longitude/latitude is
in decimal degrees, which is not a standard measure. We can find out the
units of a spatial data set by using the st_crs() function
and calling up units as follows
st_crs(homeless.sf)$units## NULLst_crs(la.city.tracts)$units## NULLBooo!. Not only do we need to reproject homeless.sf, shelters.sf, and la.city.tracts into the same CRS, we need to reproject them to a CRS that handles standard distance measures such as meters or kilometers. The Universal Transverse Mercator (UTM) projected coordinate system works in meters. UTM separates the United States in separate zones and Southern California is in zone 11, as shown in the figure below.
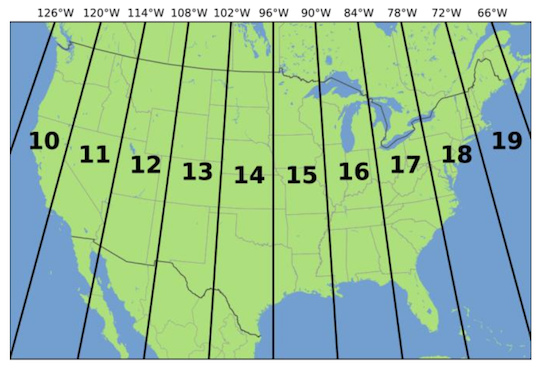
Figure 2: UTM Zones
Let’s reproject la.city.tracts, homeless.sf and
shelters.sf to a UTM Zone 11 projected coordinate system. Use
+proj=utm as the PCS, NAD83 as the datum and GRS80 as the
ellipse (popular choices for the projection/datum/ellipse of the U.S.).
Whenever you use UTM, you also need to specify the zone, which we do by
using +zone=11. To reproject use the function
st_transform() as follows.
la.city.tracts.utm <-la.city.tracts %>%
st_transform(crs = "+proj=utm +zone=11 +datum=NAD83 +ellps=GRS80")
homeless.sf.utm <- homeless.sf %>%
st_transform(crs = "+proj=utm +zone=11 +datum=NAD83 +ellps=GRS80")
shelters.sf.utm <- shelters.sf %>%
st_transform(crs = "+proj=utm +zone=11 +datum=NAD83 +ellps=GRS80")Equal?
st_crs(la.city.tracts.utm) == st_crs(homeless.sf.utm)## [1] TRUEUnits?
st_crs(la.city.tracts.utm)$units## [1] "m"st_crs(homeless.sf.utm)$units## [1] "m"st_crs(shelters.sf.utm)$units## [1] "m"“m” stands for meters.
Note that you cannot change the CRS if one has not already been
established. For example, you cannot use the function
st_transform() on homeless.sf if you did not
establish the CRS when you used st_as_sf() on
homeless.df.
Now, let’s map em all.
tm_shape(la.city.tracts) +
tm_polygons() +
tm_shape(homeless.sf.utm) +
tm_dots(col="red") +
tm_shape(shelters.sf.utm) +
tm_dots(col="blue")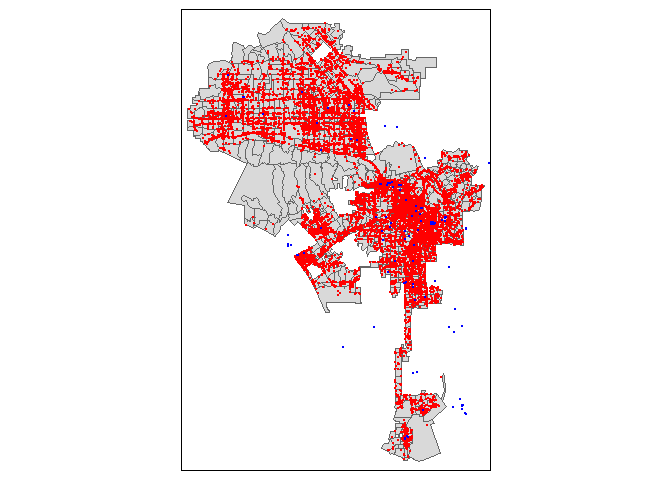
Main takeaway points:
- The CRS for any spatial data set you create or bring into R should always be established.
- If you are planning to work with multiple spatial data sets in the same project, make sure they have the same CRS.
- Make sure the CRS is appropriate for the types of spatial analyses you are planning to conduct.
If you stick with these principles, you should be able to get through most issues regarding CRSs. If you get stuck, read GWR Ch. 2.4 and 7.
OpenStreetMap
Another way to bring point data into R is to draw from the wealth of spatial data offered by OpenStreetMap (OSM). OSM is a free and open map of the world created largely by the voluntary contributions of millions of people around the world. Since the data are free and open, there are few restrictions to obtaining and using the data. The only condition of using OSM data is proper attribution to OSM contributors.
We can grab a lot of really cool data from OSM using their API. OSM serves two APIs, namely Main API for editing OSM, and Overpass API for providing OSM data. We will use Overpass API to gather data in this lab. What kinds of things can you bring into R through their API? A lot. Check them out on their Wiki.
Data can be queried for download using a combination of search criteria like location and type of objects. It helps to understand how OSM data are structured. OSM data are stored as a list of attributes tagged in key - value pairs of geospatial objects (points, lines or polygons).
Maybe were interested in the proximity of homeless encampments to
restaurants. We can bring in restaurants listed by OSM using various
functions from the package osmdata. Restaurants are
tagged under amenities. Amenities are facilities used by visitors and
residents. Here, key is “amenity” and value is
“restaurant.” Other amenities include: “university”, “music school”, and
“kindergarten” in education, “bus station”, “fuel”, “parking” and others
in transportation, and much more.
Use the following line of code to get restaurants in Los Angeles
data_from_osm_sf <- opq(getbb ("Los Angeles, California")) %>% #gets bounding box
add_osm_feature(key = "amenity", value = "restaurant") %>% #searches for restaurants within the bounding box
osmdata_sf() #download OSM data as sfWhat you get is a list with a lot of information about restaurants mapped in OSM. Let’s extract the geometry and name of the restaurant.
#select name and geometry from point data for restaurants
resto_osm <- data_from_osm_sf$osm_points %>% #select point data from downloaded OSM data
select(name, geometry) #selecting the name and geometry to plotWe get an sf object containing restaurants in Los Angeles.
Finally, we can plot the restaurants using our comrade
leaflet(), which we discovered in Lab 3.
#create a plot in leaflet
leaflet() %>%
addProviderTiles("CartoDB.Positron") %>%
addCircles(data = resto_osm)A limitation with the osmdata package is that it is rate limited, meaning that it cannot download large OSM datasets (e.g. all the OSM data for a large city). To overcome this limitation, the osmextract package was developed, which can be used to download and import binary .pbf files containing compressed versions of the OSM database for pre-defined regions.
Mapping point patterns
Other than mapping their locations (e.g. dot map), what else can we
do with point locations? One of the simplest analyses we can do with
point data is to examine the distribution of points across an area (also
known as point density). When working with neighborhoods, we can examine
point distributions by summing up the number of points in each
neighborhood. To do this, we can use the function
aggregate().
hcamps_agg <- aggregate(homeless.sf.utm["SRNumber"], la.city.tracts.utm, FUN = "length")The first argument is the sf points you want to
count, in our case homeless.sf.utm. You then include in
brackets and quotes the variable containing the unique ID for each
point, in our case “SRNumber”. The next argument is the object you want
to sum the points for, in our case Los Angeles census tracts
la.city.tracts.utm. Finally,FUN = "length" tells R
to sum up the number of points in each tract.
Take a look at the object we created.
glimpse(hcamps_agg)## Rows: 1,001
## Columns: 2
## $ SRNumber <int> 110, 32, 35, 186, 7, 3, 6, 32, 2, 37, 1, 18, 31, 11, 28, 173,…
## $ geometry <MULTIPOLYGON [m]> MULTIPOLYGON (((387834.3 37..., MULTIPOLYGON (((…The variable SRNumber gives us the number of points in each of Los Angeles’ tracts. Notice that there are missing values.
summary(hcamps_agg)## SRNumber geometry
## Min. : 1.00 MULTIPOLYGON :1001
## 1st Qu.: 10.00 epsg:NA : 0
## Median : 29.00 +proj=utm ...: 0
## Mean : 56.84
## 3rd Qu.: 69.00
## Max. :822.00
## NA's :28This is because there are tracts that have no homeless encampments.
Convert these NA values to 0 using the replace_na()
function within the mutate() function.
hcamps_agg <- hcamps_agg %>%
mutate(SRNumber = replace_na(SRNumber,0))The function replace_na() tells R to replace any NAs
found in the variable SRNumber with the number 0.
Next, we save the variable SRNumber from hcamps_agg
into our main dataset la.city.tracts.utm by creating a new
variable hcamps within mutate().
la.city.tracts.utm <- la.city.tracts.utm %>%
mutate(hcamps = hcamps_agg$SRNumber)We can map the count of encampments by census tract, but counts do not take into consideration exposure (remember the discussion regarding counts vs rates in Handout 2). In this case, tracts that are larger in size will likely have more encampments. Let’s calculate the number of encampments per area.
To calculate the number of encampments per area, we’ll need to get
the area of each polygon, which we do by using the function
st_area(). The default area metric is kilometers squared,
but we can use the function set_units() from the
units package to set the unit of measurement to (the
U.S. friendly) miles squared value = mi2. Use these
functions within mutate() to create a new column
area that contains each tract’s area.
la.city.tracts.utm<- la.city.tracts.utm %>%
mutate(area=set_units(st_area(la.city.tracts.utm), value = mi2))The class of variable area is units
class(la.city.tracts.utm$area)## [1] "units"We don’t want it in class units, but as class numeric. Convert it to
numeric using as.numeric()
la.city.tracts.utm <- la.city.tracts.utm %>%
mutate(area = as.numeric(area))Then calculate the number of homeless encampments per area.
la.city.tracts.utm<- la.city.tracts.utm %>%
mutate(harea=hcamps/area)Let’s create a choropleth map of encampments per area.
tm_shape(la.city.tracts.utm, unit = "mi") +
tm_polygons(col = "harea", style = "quantile",palette = "Reds",
border.alpha = 0, title = expression("Encampments per " * mi^2)) +
tm_scale_bar(position = c("left", "bottom")) +
tm_layout(main.title = "Homeless encampments in Los Angeles Tracts 2019",
main.title.size = 0.95, frame = FALSE,
legend.outside = TRUE, legend.outside.position = "right")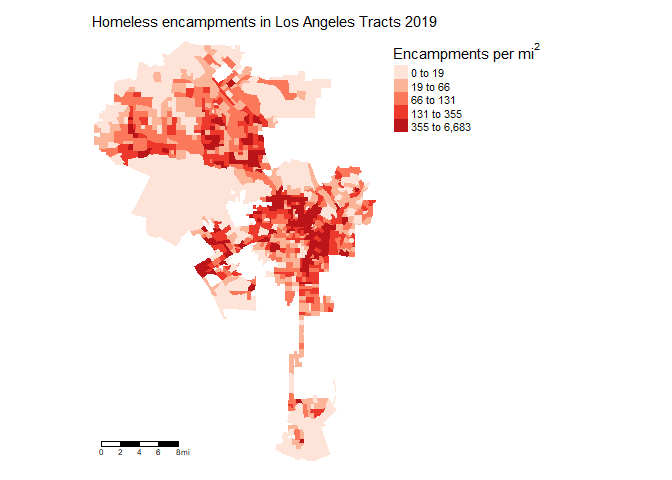
What is the correlation between neighborhood encampments per area and
percent black? What about percent Hispanic? Use the function
cor().
cor(la.city.tracts.utm$harea, la.city.tracts.utm$pnhblk, use = "complete.obs")## [1] -0.03363424cor(la.city.tracts.utm$harea, la.city.tracts.utm$phisp, use = "complete.obs")## [1] 0.01480164Practice Exercise: Instead of encampments per area, map encampments per population tpop. What is the correlation between neighborhood encampments per population and percent black? What about percent Hispanic?
Kernel density map
In Handout 2, I briefly describe the use of kernel density maps to show the spatial patterns of points. These are also commonly known as heat maps. They are cool looking and as long as you understand broadly how these maps are created and what they are showing, they are a good exploratory tool. Also, a benefit of using a kernel density map to visually present your point data is that it does away with predefined areas like census tracts. Your point space becomes continuous.
To create a heat map, we turn to our friend ggplot().
Remember that ggplot() is built on a series of
<GEOM_FUNCTION>(), which is a unique function
indicating the type of graph you want to plot. In the case of a kernel
density map, stat_density2d() is the
<GEOM_FUNCTION>(). stat_density2d() uses
the kde2d() function in the base MASS
package on the back end to estimate the density using a bivariate normal
kernel.
Let’s create a heat map with stat_density2d() where
areas with darker red colors have a higher density of encampments.
ggplot() +
stat_density2d(data = homeless.df,
aes(x = Longitude, y = Latitude,
fill = ..level.., alpha = ..level..),
alpha = .5, bins = 50, geom = "polygon") +
geom_sf(data=la.city, fill=NA, color='black') +
scale_fill_gradient(low = "blue", high = "red") +
ggtitle("Homeless Encampments Heat Map") +
theme_void() +
theme(legend.position = "none")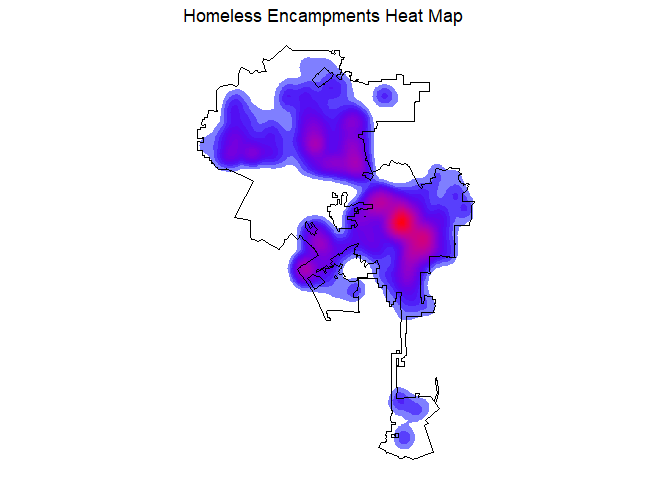
Rather than the sf object homeless.sf.utm,
we use the regular tibble homeless.df, and indicate in
aes() the longitude and latitude values of the homeless
encampments. The argument bins = 50 specifies how finely
grained we want to show the variation in encampments over space - the
higher it is, the more granular (use a higher value than 50 to see what
we mean). The argument alpha establishes the transparency
of the colors (it ranges from 0 to 1). We add the Los Angeles city
boundary using the geom_sf(), which is the
<GEOM_FUNCTION>() for mapping sf
objects. We use scale_fill_gradient() to specify the color
scheme where areas of low encampments density are blue and areas of high
encampments density are red.

This
work is licensed under a
Creative
Commons Attribution-NonCommercial 4.0 International License.
Website created and maintained by Noli Brazil